Netcode Concepts Part 1: Introduction
A series on general concepts in Netcode
Index
Part 1: Introduction
Part 2: Topology
Part 3: Lockstep and Rollback
What is “Netcode”?
In order for multiple players on different machines to play games together, a mechanism is needed to keep all machines in-sync so that players see an accurate and consistent representation of the game state, and to allow players a way for their inputs to affect this shared game state.
This game state represents the current state of the game session (or in the case of an MMO, the current state of the game world), and includes things like the location and movement of all the players, NPCs, or units; bullets and projectiles; and the value of stats like scores, money, and resources. Game events like movement, collision and hit checks, and spawning projectiles, act on the game state, and can originate from a player’s input, or from the game engine as it processes NPC actions. The state and/or events that affect it must be synchronised in some way between all machines; otherwise, objects that one player sees on their machine are not where they are for another player, leading to confusing or unfair gameplay.
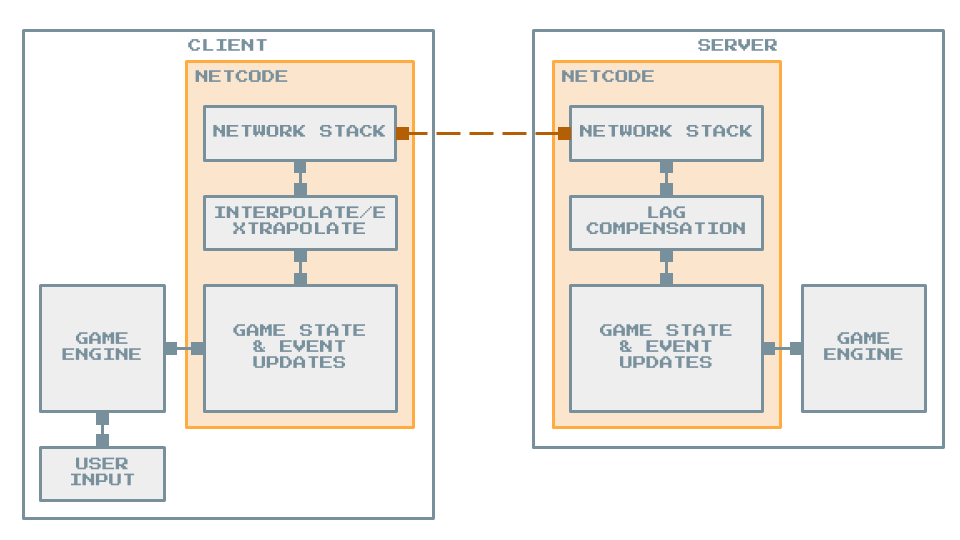
Doing all of this synchronisation across different machines potentially running at different speeds, while dealing with the physical limitations of networks such as like latency/lag, packet loss, and limited bandwidth, all fall under this blanket term “Netcode”.
Why Netcode is Hard: Latency
Latency in networking is the time it takes for a signal to go from its source to its destination. When dealing with Netcode, one can never assume that a signal can get from A to B instantaneously, and in fact a large proportion of netcode exists simply to deal with this fact.
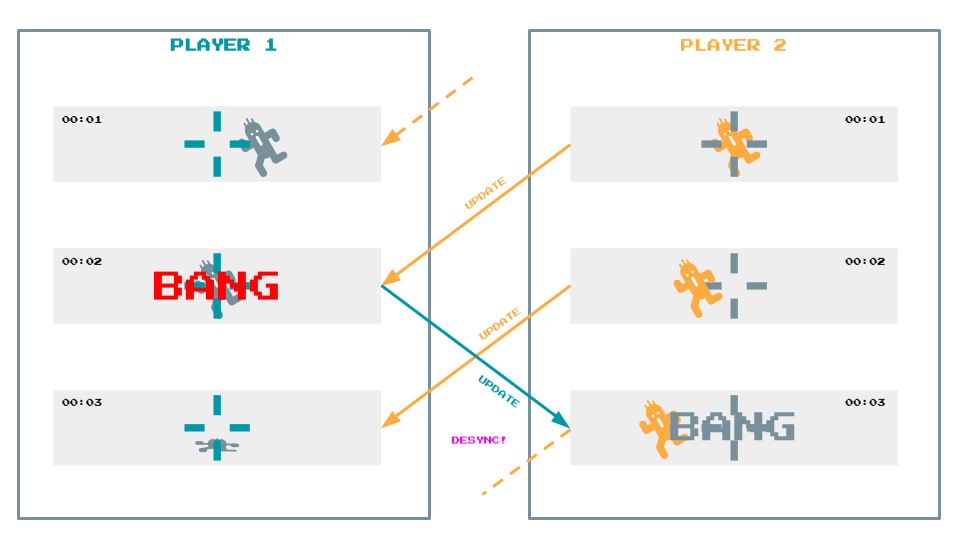
When there is latency between two machines, any event generated on one machine takes some time to reach the other machine. If this delay is sufficiently long, then the game state in the other machine may have moved on, and as a result the event is applied to a slightly different game state on one machine versus the other, leading to a different outcome.
In a basic example of this, imagine a simple (and fundamentally flawed) FPS game, in which a player shoots at another player who at that moment is exactly in their cross-hairs; that shoot event is sent to the other player, and takes a small amount of time to arrive. Due to network latency, by the time that event arrives, the game state on the other player may have since updated to where they are no longer lined up with the cross-hairs. The result is a hit on one machine, and a miss on the other. If this latency is unaccounted for, the game states on the two machines are no longer synchronised.
The base latency of a network connection is primarily caused by the following three things:
1. The fundamentally unbreakable physical speed limit: the speed of light
No signal can travel faster than the speed of light, no matter how good our technology gets. Consider a player in Sydney connecting with a server in New York, an over-the-globe distance of 16 thousand kilometers (or 10 thousand miles). A signal travelling at the speed of light takes 53 milliseconds to do this distance.
In reality, the actual distance travelled by the data is much greater, as the data must travel via an internet connection to a local exchange, onto the national internet backbone in Sydney, dive down into an undersea fibre-optic cable that winds is way out of Australia, running along the ocean floor to Fiji and then Hawaii, which plugs into America somewhere along the coastline of Washington State, before hopping into an overland fibre that runs to Chicago, then another fibre that runs from Chicago to New York, where finally finds its way to the server.
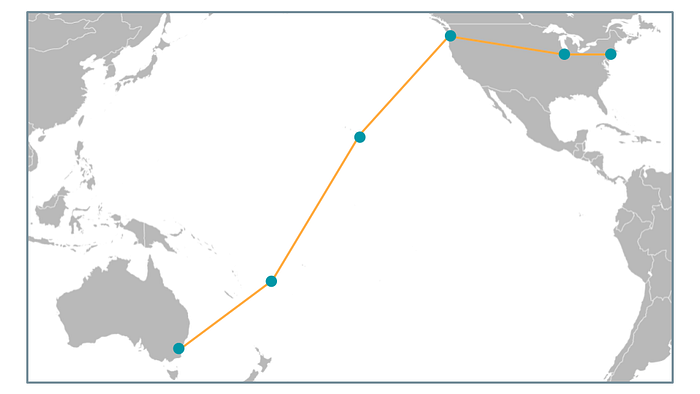
Furthermore, light travels slower in a fibre-optic cable than it does in air or vacuum, possibly up to 30% slower. So this 53ms latency figure might easily be more like 80ms due to the extra distance, and slower travel speed.
2. Packet routing delays
At multiple point along that epic journey, the data packet has to be read by some network equipment which must decide which line to send the data down next. This requires part of the data packet to be read into a processor inside the network equipment, its destination address extracted and matched against a routing table, before being routed down the correct line hopefully towards a network node that is one step closer to the intended destination.
Unfortunately it takes time to do this, and each time it happens, a small delay is added to the total trip time of that data. That 80ms of signal propagation delay might become 100ms after factoring in the delay caused by the sheer number of network nodes that have to route the data to get it to its destination.
3. Round-trips, acknowledgements, and re-transmission
Depending on the networking protocol used, and the possibility for packet loss, it may take more than one trip down this line to complete the data transmission. For example, TCP packets require a receive acknowledgement from the destination machine to ensure that a piece of data was correctly transmitted; if no acknowledgement is received, or if the data received was corrupted or incomplete, the sender will retry the re-transmission.
This means with TCP and other protocols that require an acknowledgement, it can take at best one round-trip to finish each data transmission, and at worse (in the case of data loss and re-transmission attempts) multiple round trips. In the Sydney to New York example previously, which is now clocking in at 100ms due to propagation and routing delays, the round-trip time doubles this time to 200ms; and each additional re-transmission attempt becomes a multiple of this number.
This player therefore has a ping (the round-trip-time) of 200ms in the best case scenario. It can’t get any better than that, and in fact can get significantly worse in the event of network congestion, network outages, packet loss and route updates, all of which can introduce temporary additional latency (also known as a lag spike).
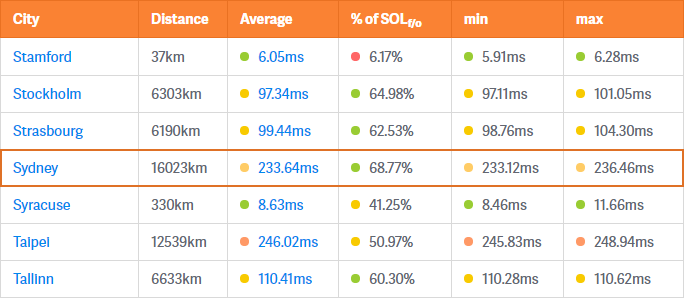
Fortunately for local network multiplayer games, the latency situation is a lot better, with ping times of 1ms or lower for computers on the same wired local network, or times of 4ms or lower for computers on the same wireless network with the latest WiFi standards. Nevertheless, even if a game is designed to be only played on a local network with a sub-1ms network latency, latency must be correctly accounted for by netcode, as there is still the very real chance of an unexpected latency spike caused by the network or by a computer’s own internal machinations. Even a single latency spike can be sufficient to de-synchronise a game not built to handle latency.
In the Part 2, we will talk about the different ways game clients can connect to each other, with or without a dedicated game server.
